「急にネットが重くなった…。ルータの故障?プロバイダ?それともどこかの経路?」
そんなときに役立つのが traceroute(Windowsでは tracert) です。
この記事では、Windows PCとCiscoルータ/スイッチを前提に、
- tracerouteが「何をしているツールなのか」
- 結果をどう読めばいいのか
- 現場でどういう考え方で使えばいいのか
を、研修用としても使えるレベルで整理していきます。
本記事のゴール
このページを読み終わるころには、次のことができる状態を目指します。
- pingとの違いを説明できる
- Windowsの
tracertを使って経路を確認できる - Cisco機器の
tracerouteのざっくりした仕組みと注意点を理解している - 結果を見て「ありそうなボトルネック」を推測できる
(ただし“断定はできない”という感覚も掴んでいる)
traceroute(tracert)は、通信経路のどこで問題が起きているかを確認するためのコマンドです。
もし「そもそも通信できているか分からない」という場合は、先に ping コマンドの基本的な使い方を確認してから読むと理解しやすくなります。
Tracerouteのイメージ:各駅停車の「通過駅」を見に行く
まずはイメージから。
あなたが東京駅から大阪駅まで新幹線で移動するとします。
普通は「東京で乗った」「大阪で降りた」ぐらいしか意識しませんよね。
でも途中で止まったり遅れたりすると、
- 「今どのあたりなんだろう?」
- 「名古屋までは順調だったのかな?」
と、途中の駅(経由地)が気になるはずです。
Tracerouteは、まさにこの「途中の駅」を1つずつ洗い出してくれるツールです。
- あなたのPC(出発駅)
- 家庭用ルータや社内ルータ(途中駅)
- プロバイダやインターネット側のルータ(さらに途中駅)
- 相手サーバ(終点)
といった感じで、どのルータ(ホップ)を通って目的地にたどり着いているかを一覧で見せてくれます。
pingとtracerouteの違い
ping:終点まで行けるかを確認するツール
pingは基本的に、
- 「相手(サーバ)まで届くか?」
- 「往復に何ミリ秒かかるか?」
だけをチェックします。
途中のルータがどうなっているかは分かりません。
traceroute:途中経路を1ホップずつたどるツール
一方tracerouteは、
- 途中のルータ1台1台に名前とIPアドレスを付けて見せてくれる
- 各区間ごとの往復時間(RTT)も表示してくれる
という点が大きな違いです。
つまり、
- ping:ゴールに着くかどうか
- traceroute:ゴールに着くまでの道のり
を確認するツール、とイメージするとわかりやすいです。
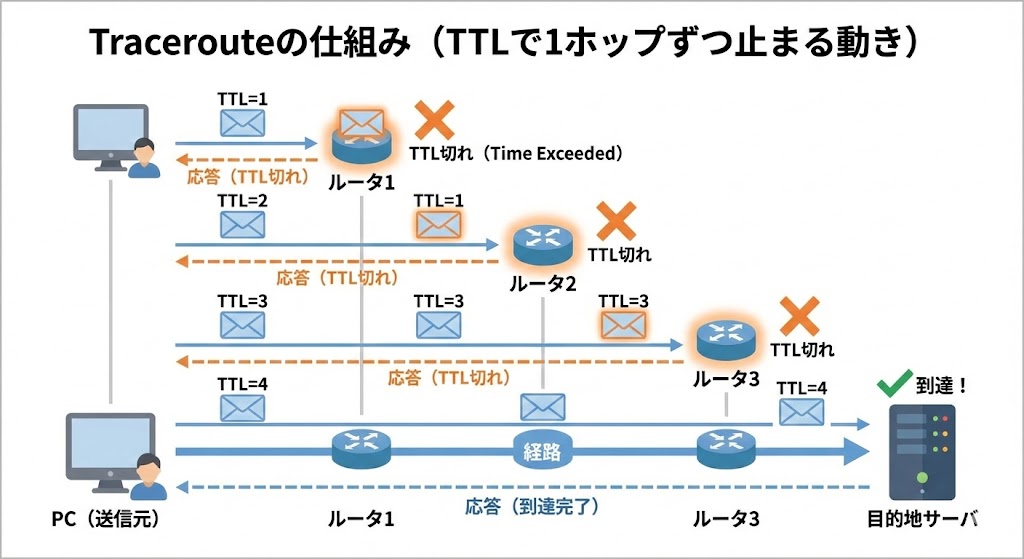
仕組みのキモ:TTL(Time To Live)をわざと使い切る
TTLとは?ざっくり「寿命カウンタ」
IPパケットには TTL(Time To Live) という値が入っています。
これは簡単に言うと、
「このパケットはルータを何回までくぐっていいか?」
という 寿命カウンタ です。
- パケットがルータを1台通るたびに、TTLが1ずつ減る
- TTLが0になったところで、パケットは破棄される
- そのとき、「Time Exceeded」というエラーメッセージ(ICMP)が元の送信元に返される
というルールになっています。
tracerouteはTTLを少しずつ増やして経路を特定する
tracerouteは、このTTLの性質をうまく利用しています。
- TTL=1でパケット送信
- 最初のルータでTTLが0になって破棄される
⇒ そのルータから「Time Exceeded」が返ってくる
⇒ 「1ホップ目のルータ」が分かる
- 最初のルータでTTLが0になって破棄される
- TTL=2でパケット送信
- 1ホップ目は通過、2ホップ目でTTL=0
⇒ 「2ホップ目のルータ」が分かる
- 1ホップ目は通過、2ホップ目でTTL=0
- これをTTL=3,4,5…と繰り返し
- 最終的に、目的地からは別のICMP(Port Unreachableなど)が返ってくる
⇒ 「終点に到達した」と判断
- 最終的に、目的地からは別のICMP(Port Unreachableなど)が返ってくる
こうして、1ホップずつ“寿命切れ”させながら経路を洗い出すのがtracerouteの基本動きです。
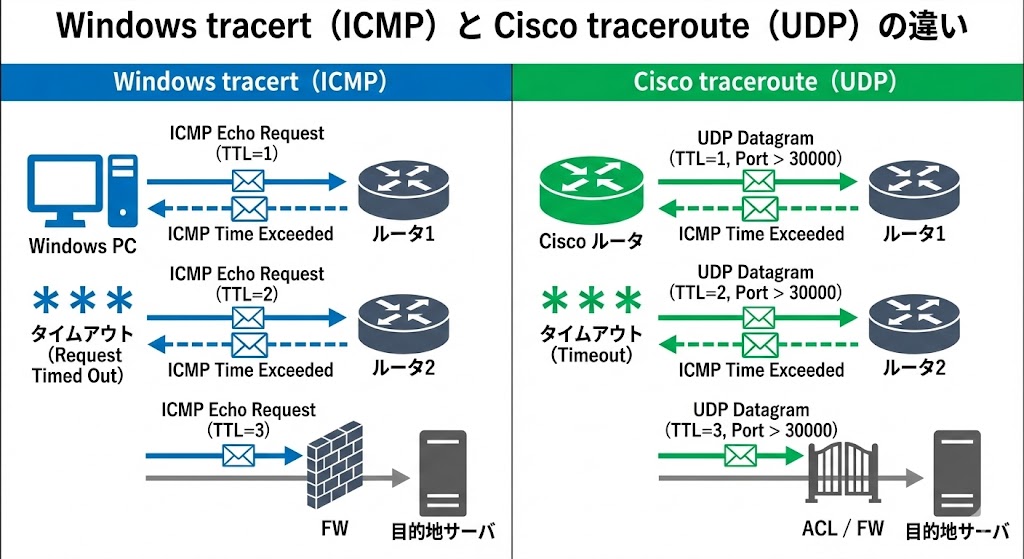
Windowsのtracert:ICMPベースのtraceroute
Windows tracertの特徴
Windowsの tracert コマンドは、
- ICMP Echo Request(pingと同じ種類のパケット)を使う
- TTLを1,2,3…と変えながら送信する
という動きをします。
基本的な使い方はシンプルです。
C:\> tracert google.com
google.com の部分は、調べたいホスト名やIPアドレスに変えてOKです。
結果の見方(Windows例)
トレースを実行しています。google.com [142.250.xxx.xxx] までの経路:
1 <1 ms <1 ms <1 ms 192.168.1.1
2 10 ms 12 ms 11 ms 203.0.113.1
3 15 ms 14 ms 16 ms ...
4 * * * 要求がタイムアウトしました。
見方のポイントはこの3つです。
- 左端の数字:ホップ数(何番目のルータか)
- IPアドレスやホスト名:そのルータのアドレス
- 右側の3つの時間(ms):そのルータまでの往復遅延(RTT)
RTTが「10ms → 12ms → 11ms → 150ms → 180ms…」のように、
あるホップを境に大きく跳ね上がっている場合、そのホップやその先のネットワークが「怪しそう」という推測ができます。
ただしこれはあくまで“推測”であって、犯人確定ではないことが重要です(後で詳しく触れます)。
Ciscoルータ/スイッチのtraceroute:UDPベースで動く
Cisco tracerouteはUDPを使う(※ここ超重要)
Cisco IOSの traceroute は、デフォルトではUDPパケットを使います。
- 宛先ホストの「到達しないはずのUDPポート番号」に向けてパケットを送信
- TTLを1,2,3…と増やしていく
- TTLが0になった場所からは ICMP Time Exceeded が返る
- 最終的に宛先に届くと、宛先から ICMP Port Unreachable が返る
⇒ これで「終点まで到達した」と判断
Windowsの tracert はICMP、Ciscoの traceroute はUDP(デフォルト)。
この違いのせいで、FW(ファイアウォール)やACL、NATの影響を受け方が変わり、結果表示も変わることがあります。
Ciscoでの実行例(基本)
Router# traceroute 8.8.8.8
シンプルに宛先IPだけを指定する使い方が多いです。
オプションを指定してICMPやTCPを使うこともできますが、まずは「デフォルトはUDPで飛んでいる」ことだけは覚えておきましょう。
なぜUDPだと結果が変わるのか?(FW / ACL / NATの影響)
FW / ACL でUDPまたはICMPがブロックされる
経路上にファイアウォールやACLがある場合、
- Windowsの
tracert(ICMP)だけがブロックされる - Ciscoの
traceroute(UDP)だけがブロックされる - あるいは両方ブロックされる
といったパターンが普通に起こります。
その結果、
- Windowsからは途中で
* * *になって見えないが
Ciscoからは最後まで見える - Ciscoからは途中で止まるが
Windowsからは最後まで見える
といった結果の違いが出ます。
これは「おかしい」のではなく、“通しているプロトコルが違うから挙動も違う”と理解しておくと納得しやすいです。
NAT機器をまたぐときの注意
NAT(アドレス変換)を行うルータやFWをまたぐ場合も、tracerouteの挙動が変わることがあります。
- NAT機器が戻りのICMPを落としている
- 特定のUDPポートだけ通さない設定になっている
といった理由で、
- あるホップから急に
* * *になる - 途中からホップ数が飛んだように見える
などの現象が出ます。
「NATやFWで制御されているかもしれない」前提で読むのが、実務エンジニアの視点です。
Traceroute結果の読み方:どこをどう見るか
各項目の意味
一般的な出力は、WindowsでもCiscoでもだいたいこんな構造です。
1 192.168.1.1 1 ms 1 ms 1 ms
2 203.0.113.1 10 ms 12 ms 11 ms
3 198.51.100.1 25 ms 24 ms 26 ms
4 * * * *
見るポイントはシンプルに3つ。
- ホップ数
- 経路上で何台目のルータか
- アドレス/ホスト名
- どのネットワークの機器か、おおよその位置
- RTT(往復時間)
- そのホップまでの往復遅延
- 同じホップに対して3回測った値が並ぶ
「遅延が増えている=そこで詰まっている」とは限らない
よくある誤解が、
あるホップからRTTが大きくなった ⇒ そのホップがボトルネックの犯人!
と 断定してしまうことです。
現場では、次のような要因で単純にそう言い切れないケースが多くあります。
- 途中のルータが ICMPやUDPの優先度を下げている
(制御用トラフィックを優先、tracerouteは後回し) - 非対称ルーティング(行きと帰りで通る経路が違う)が発生している
- 経路上で ロードバランス していて、測定ごとに違うルートを通っている
- 単にその瞬間だけ一時的な負荷が高かった
そのため、tracerouteで見えるのはあくまでも
「怪しそうな区間の候補」「状況を推測するための材料」
に過ぎません。
ボトルネック“らしき場所”を特定 → 監視情報やログ、別経路のテストで裏を取る
というのが、実務での基本スタンスです。
「***」や途中で止まるときの考え方
「***」は故障ではなく“回答拒否”なことが多い
出力の中に、こんな行が出ることがあります。
3 * * * 要求がタイムアウトしました。
初心者がここでよくやる勘違いが、
3ホップ目が死んでる!(障害だ!)
と決めつけてしまうこと。
実際には、次のような理由がほとんどです。
- FWやACLで、ICMPやUDPの応答が遮断されている
- ルータ側で、ICMP応答のレート制限がかかっている
- 回答する設定になっていない、もしくは管理上あえて返していない
この場合でも、その先のホップが表示されているなら、
経路としては普通に通っていることが多いです。
✅ ポイント:
***が出た=そのホップが障害、ではない。
まずは「セキュリティ設定や制限で返事していないだけかも」と疑う。
本当に「途中で切れている」ケース
一方で、次のようなパターンは要注意です。
- あるホップから先が全く表示されない
- その宛先へのpingも通らない
- 他の経路(別拠点や別プロバイダ)からは到達する
このような場合は、
- その手前〜そのホップ付近での障害
- ルート不整合
- FWの設定ミス
などを疑う価値があります。
とはいえ、tracerouteだけで「ここが絶対に障害ポイント」と断定はできません。
あくまで“このあたりが怪しい”という絞り込みに使うツールだと割り切っておきましょう。
実務での使い方ステップ(若手エンジニア向け)
ステップ1:まずはpingでざっくり確認
- 宛先サーバへの ping
- 同じネットワーク内の別サーバへの ping
- デフォルトゲートウェイ(ルータ)への ping
ここで、
- どこまで届いてどこから届かないか
- 遅延がどの程度か
をざっくり把握します。
ステップ2:tracerouteで“怪しい区間”を探す
次に、Windowsの tracert やCiscoの traceroute を使って経路を確認します。
- 社内ネットワークの出口までは正常か?
- プロバイダ以降で急に遅延が増えていないか?
- 途中で
***になっている機器は、FWやインターネット側のルータではないか?
など、“どのゾーンが怪しいか”を切り分けるイメージで見ます。
この時点ではまだ「推測」の段階です。
ステップ3:ログ・監視・別経路で裏取りする
tracerouteで怪しく見えた区間について、
- 監視ツール(SNMPグラフ、インターフェース利用率)
- ルータ/FWのログ
- 別経路(他拠点、他プロバイダ)からの疎通テスト
などで、本当にそこがボトルネックか確認するのが、実務での一連の流れです。
tracerouteは「仮説を立てるツール」であって、
「原因を確定するツール」ではない。
この意識を持っておくと、現場での評価がグッと上がります。
tracerouteを使うときの注意事項
1. traceroute万能論は捨てる
- すべてのルータがICMP/UDPにきちんと応答するとは限らない
- 経路は時間帯や経路制御により変わる
- ネットワーク外側(インターネット側)は、こちらからはコントロールできない
ので、結果がきれいに並ばない方が普通です。
2. 「途中で止まる=障害」と思い込まない
- FW/ACL/NAT設定
- 応答レート制限
- “そもそも返さない運用ポリシー”
など、設計・運用上の理由で止まって見えることが多いです。
止まった地点が社内ネットワークなのか、インターネット側なのかも意識して見ましょう。
3. ICMPとUDPの違いを理解する
- Windows:ICMPベース(
tracert) - Cisco:UDPベース(
traceroute、デフォルト)
プロトコルが違えば、FWやルータの扱いも変わります。
**「OSや機器によって見える世界が違う」**という前提で結果を比較できると、一段上の見方になります。
4. Macについて
Macにも traceroute コマンドがありますが、
本記事では Windows(tracert)とCisco機器 に対象を絞って説明しました。
「Macも含めて検証したい」場合は、別途コマンド仕様を確認してください。
まとめ
- tracerouteは、途中のルータを1ホップずつ可視化するツール
- Windowsの
tracertは ICMP、Ciscoのtracerouteは UDP(デフォルト) で動く - FW / ACL / NAT の設定により、OSや機器ごとに結果が変わるのは普通
***や途中で止まる現象は、「障害」とは限らず、多くは“返事しない設定”- 「遅延が増えているホップ=ボトルネック」とは断定せず、
あくまで“怪しい区間の候補”として扱い、ログや監視と合わせて判断する
現場の初級エンジニアとしては、
- pingでざっくり到達性を確認
- tracerouteで怪しい区間を推測
- 監視やログで裏を取る
この3ステップを意識して使いこなせるようになればOKです。
「ネットが遅い」と言われたときに、なんとなくtracerouteを打つのではなく、
“何を確認したくて実行しているのか”を説明できるエンジニアを目指していきましょう。